Převod řeči na text
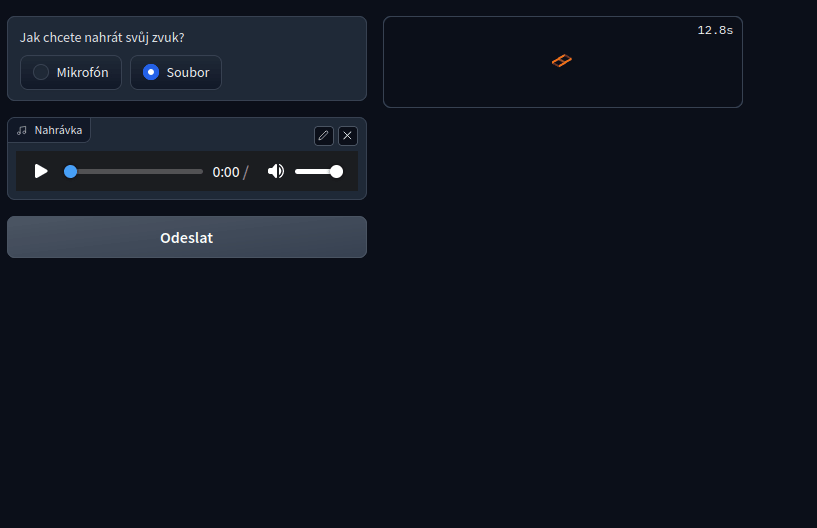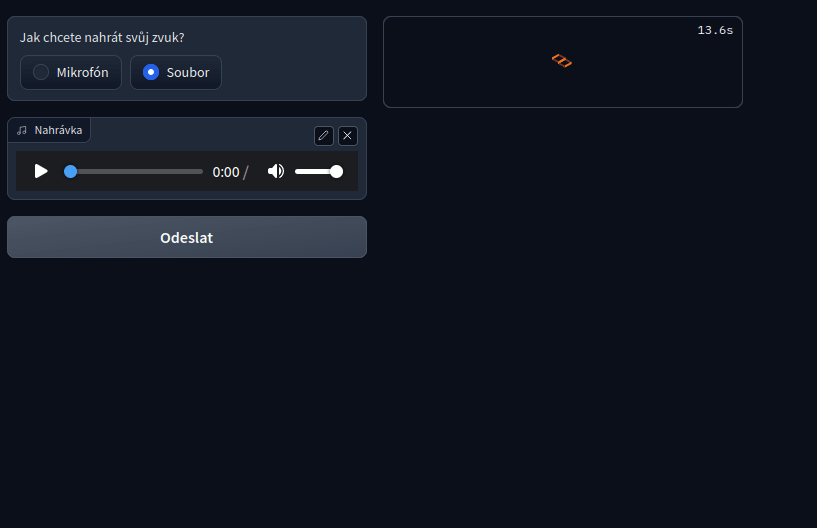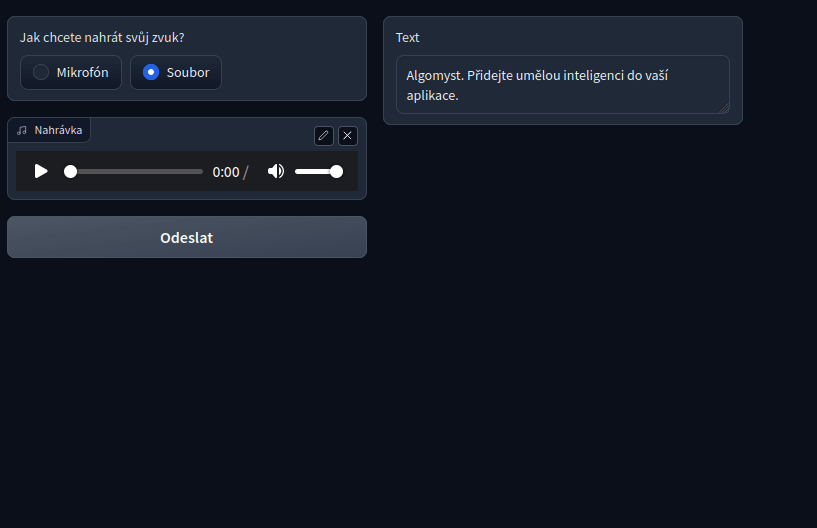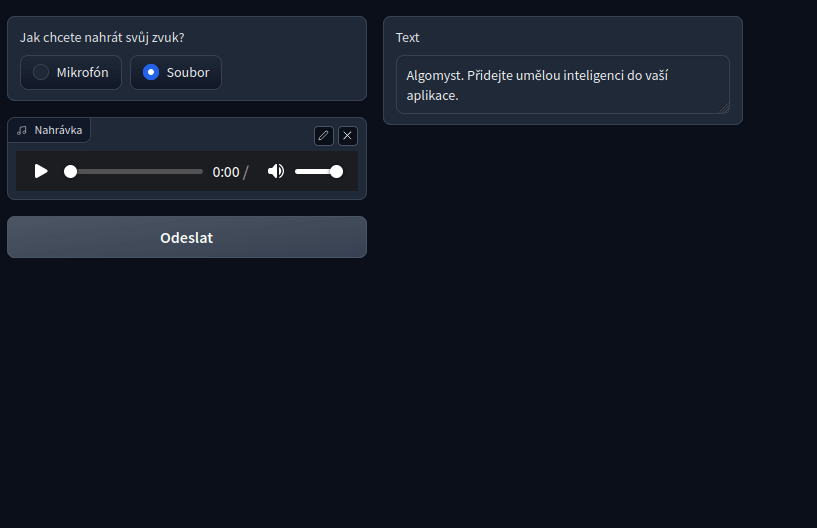
Ukázka toho jak funguje model na rozpoznávání řeči nastavený pro český jazyk.
Příklad populárního modelu Whisper od OpenAI, bežícího na CPU na našem serveru. Pro zlepšení přesnosti lze tyto modely dotrénovat na vašich datech.
Více informací o zpracování zvuku najdete zde.
Kontaktujte nás pro zprostředkování ukázky.